One Monday morning, right when the coffee machine was booting up, our alert and monitoring system went way out of whack! Amber’s systems were almost at the brink of crashing. Unlike us, she doesn’t take the weekends off and high performers like her are always at the risk of burning out.
Our initial suspect? A pileup of requests and a spike in CPU usage made us believe this was a DOS attack. But it’s never a DOS attack!
Further inspection pointed us to an internal issue where the nginx logs showed response from our sockets which was choked due to an unending loop of reconnects and failures. The chat module was buckling under the immense load on our EC2 instance.
What went down?
We rely on automated cron jobs to send out reach-out emails and invite employees to chat with Amber. Successive on-boarding of new clients in the previous week had drastically increased the volume of chats to be sent out to employees which further put a load on our chat generation module. Specifically, with a centralised server to process requests for all 4 modules, chats were triggering to over 30,000 people throughout the day, creating bottlenecks at nginx and choking our system’s request processing capability.
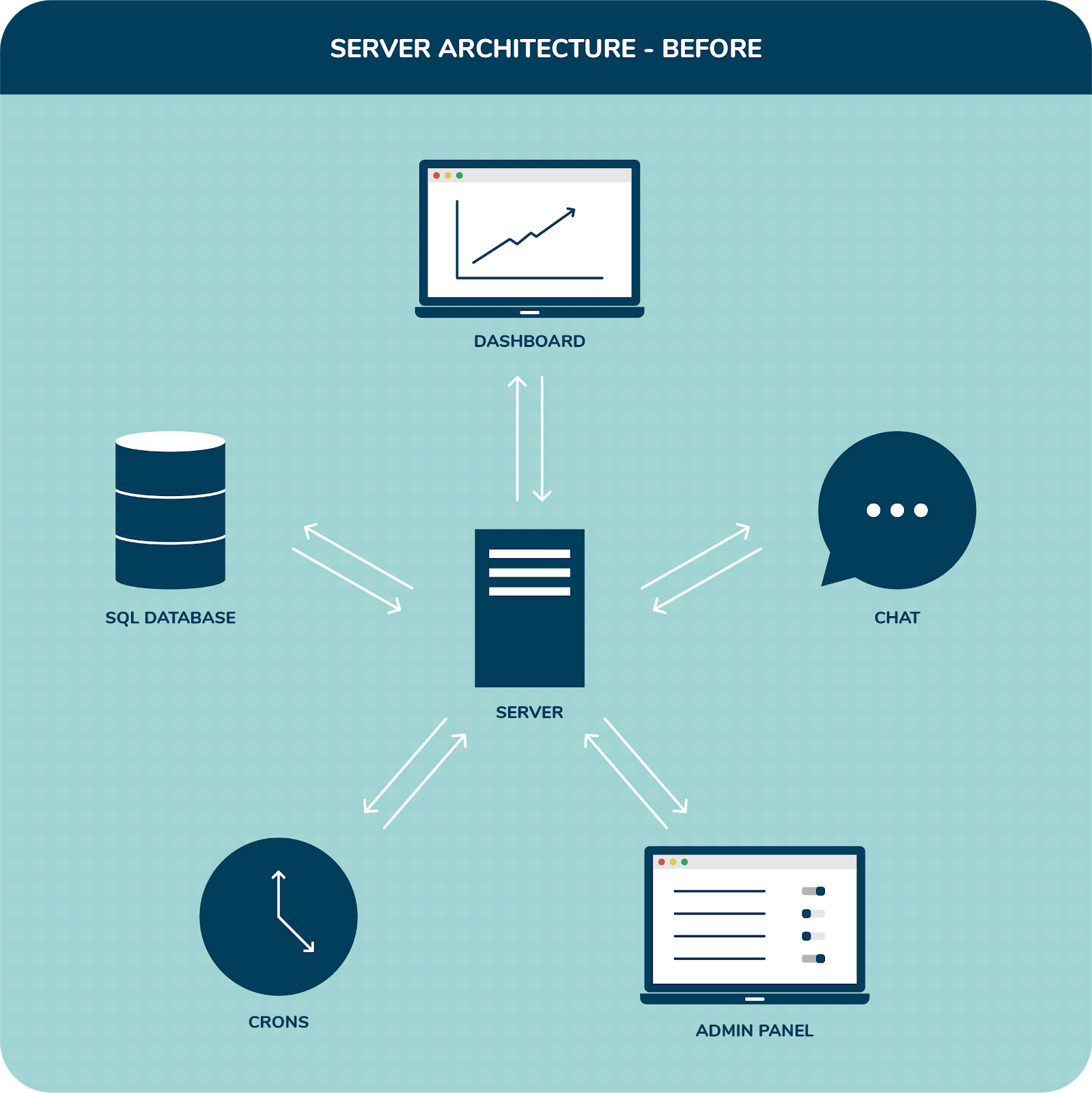
The problem could have been solved over the first can of Red Bull. We would just have to bump up the servers to handle the extra load. But that’s easier said than done since the IPs associated with our EC2 wasn’t elastic. Moreover, the existing IP associated with our EC2 was whitelisted at multiple client IT admin sites so we couldn’t just bump up our resources and risk dynamic IP shuffling. That would make a mess at the Sales side, and nobody likes talking to Sales on a Monday morning!
How we fixed it
So a long overdue tech optimisation which would isolate our different modules to their own independent servers had to be expedited.
We began by creating a read replica of our master database running on RDS.
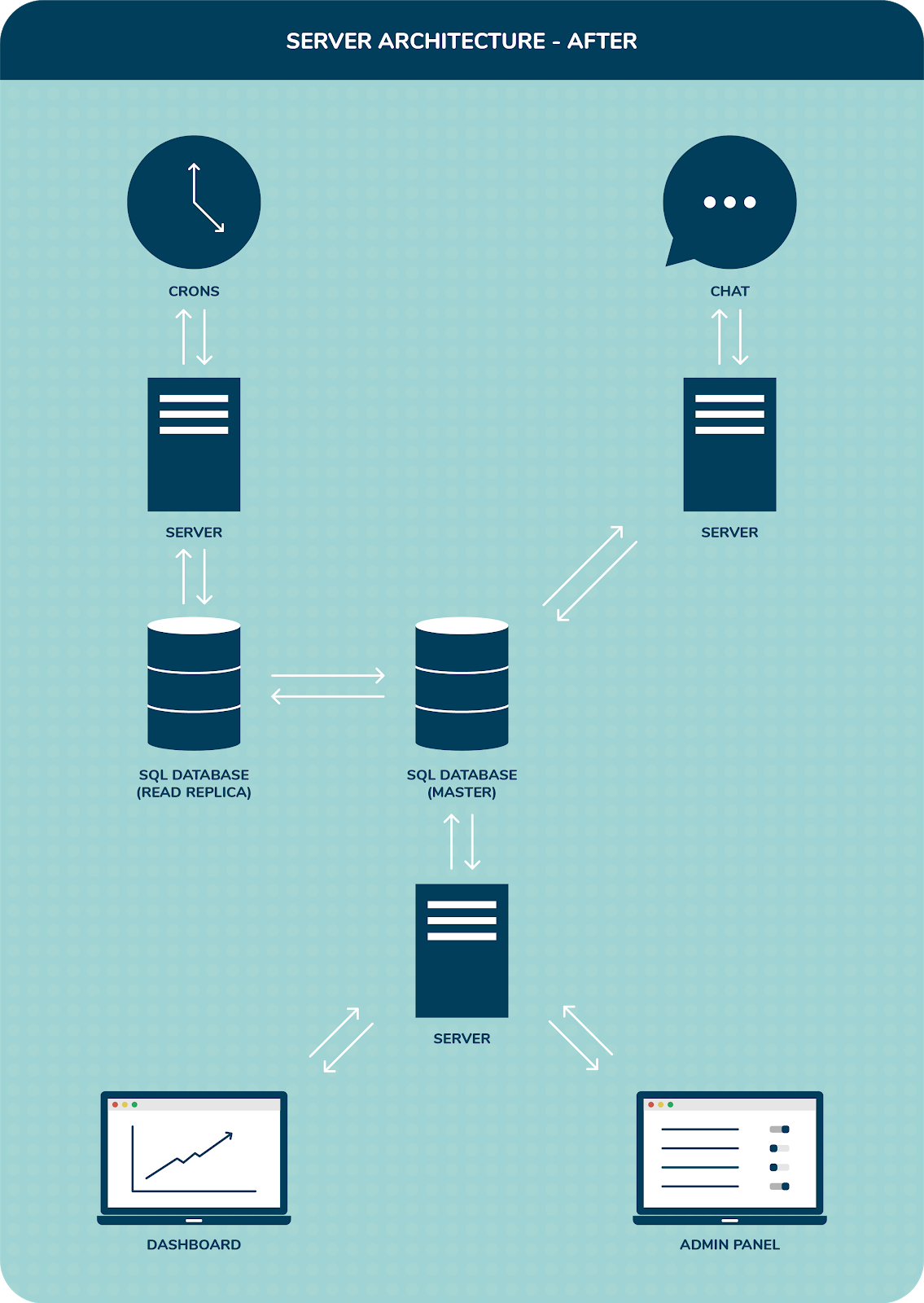
Next, we moved the cron jobs to their own server and connected it to the read replica to bear the load of the GET requests from the API, fetch data, do its job, and go to rest. The chat interface was also separated to a new server, but this one was kept tied to our master database to log in real-time chat responses and run sentiment analysis on top of it. The dashboard and admin panel shared a single server, and were tied to the master database.
Lessons learnt
48 hours and countless cans of Red Bull later, we were back in game!
After a reboot, all systems ran flawlessly and allowed the dashboard and chat to function without getting bottlenecked by the number of requests.
In effect, we had increased our capacity to accommodate 20 times more users.
3 takeaways for engineers in high-growth tech startups
1. Approach to implementing Micro-services should be structured: Before beginning it at code, take a closer look at your systems and architecture. Take an MVP approach and ship fast!
2. Alerting and monitoring (CPU usage) is like your ECG: More important than the actual health of your heart! Do not wait for 100%!
3. Horizontal scaling versus vertical scaling: Decide which one works for you. Take a vertical approach if it works for you for the short term and you want to add more resources. Eventually, you will need to spread out the load and hence horizontal scaling will become inevitable.
3 holistic takeaways
1. Make engineering growth a top business priority
Engineering forms the backbone of a product-first business. There are many ways to respond to a technical crisis like this. Don’t give into fear and start refactoring and rebuilding the system from ground-up. Take a step back, run a root cause analysis, and trust the engineering team to come up with a rational solution.
2. Accept that there are no perfect systems
It was an entirely surreal experience to see that while our system was rock solid, we have to keep making it stronger to match the pace of growth. Although this exercise brought us one step closer to adopting a microservice architecture, it also taught us that what’s working for us today could be rendered absolutely inadequate sooner than we think.
3. Cut down on Red Bull
We could have taken a little less than 48 hours to troubleshoot the issue but we realised that liquid intake volume is directly proportional to the number of toilet breaks required. We may have solved the problem in just two days but the caffeine kept us up for three.
Trusted by 330+ CHROs
See why global HR teams rely on Amber to listen, act, and retain their best people.